Google's Search AI: Training On Web Content Despite Opt-Outs

Table of Contents
How Google's Search AI Uses Web Data for Training
Google's AI algorithms require massive datasets for training. This training fuels improvements in search accuracy, natural language processing, and personalized results. Understanding how Google obtains and uses this data is crucial.
The Scale of Data Collection
The sheer volume of data Google collects is staggering. It encompasses not only text but also images, videos, and other forms of web content. While the precise size of Google's index remains undisclosed, it's widely acknowledged to be one of the largest datasets in existence. This scale allows Google's Search AI to learn intricate patterns and relationships within the web, leading to more sophisticated search capabilities. Keywords like "Google Search AI data," "web data training," and "AI training datasets" highlight the immense scope of this undertaking.
The Role of Web Crawlers
Google's web crawlers, primarily Googlebot, tirelessly traverse the internet, indexing billions of web pages. These crawlers follow links, extract content, and store it in Google's index. The process involves parsing HTML, extracting text and metadata, and analyzing various aspects of the webpage. While the robots.txt protocol allows website owners to specify which parts of their site should not be crawled, its effectiveness in preventing data collection for AI training is limited. This highlights the importance of understanding keywords like "Googlebot," "web crawling," and "robots.txt limitations."
The AI Training Process
The data collected by Googlebot fuels the training of sophisticated AI models. These models, often employing machine learning algorithms and natural language processing techniques, learn to understand the context, meaning, and relevance of web content. The more comprehensive and representative the training data, the more accurate and effective these AI models become. This process relies heavily on the vast quantity and diversity of web data, making "machine learning algorithms," "natural language processing," and "AI model training" central to Google's search advancements.
The Effectiveness of Website Opt-Outs
Website owners often utilize various methods to control access to their content, but their effectiveness against Google's AI data collection is debatable.
Robots.txt and its Limitations
robots.txt is a file that allows website owners to instruct web crawlers which parts of their site should not be accessed. However, robots.txt primarily affects search indexing, not necessarily the collection of data for AI training. Google may still collect data from pages disallowed by robots.txt, particularly for the purpose of training its AI models. Understanding the limitations of "robots.txt effectiveness," "data scraping prevention," and "AI data privacy" is key for website owners.
Noindex Meta Tags and Their Impact
The noindex meta tag instructs search engines not to index a specific page. While effective for preventing a page from appearing in search results, its impact on AI training data collection is unclear. Google may still use data from pages marked noindex, particularly for training purposes. The debate continues regarding the effectiveness of "noindex meta tag" in preventing data from being used in "AI data protection" and "search indexing."
Other Opt-Out Mechanisms and Their Efficacy
Currently, there are no universally effective mechanisms to entirely prevent a website's data from being used in Google's AI training. Efforts to limit data collection often revolve around strategies to minimize the attractiveness of a website as training data, such as limiting publicly accessible information. Further research into "data privacy," "website data protection," and "prevent AI training data" is crucial to develop more effective strategies.
The Ethical and Legal Implications
Google's data collection practices raise several ethical and legal concerns.
Privacy Concerns
The vast scale of data collection inherently raises privacy concerns. Personal information, unintentionally included on websites, could be used in AI training without explicit consent. This raises questions about compliance with regulations like GDPR and CCPA. Keywords like "data privacy concerns," "GDPR," "CCPA," and "AI ethics" highlight the complex legal and moral considerations.
Copyright Issues
The use of copyrighted web content for AI training without permission raises potential copyright infringement concerns. The legal landscape surrounding AI training data and copyright is still evolving, creating uncertainty for website owners and content creators. Understanding the issues surrounding "copyright infringement," "AI copyright," and "data ownership" is critical.
Conclusion: Navigating the Future of Google's Search AI and Web Content
Google's reliance on web data for training its Search AI is a double-edged sword. While it fuels advancements in search technology, it raises significant ethical and legal concerns regarding data privacy and copyright. Website owners currently have limited control over how their content is used for AI training, despite utilizing tools like robots.txt and noindex tags. The future will likely require a clearer legal framework, new technological solutions, and greater transparency from Google regarding its data usage.
Stay informed about updates regarding Google's Search AI training on web content and explore strategies for protecting your website data. Further research and discussion on the ethical and legal implications of AI training data are crucial for navigating this evolving landscape.
Featured Posts
-
 Marvels Quality Control Addressing Concerns About Recent Films And Series
May 05, 2025
Marvels Quality Control Addressing Concerns About Recent Films And Series
May 05, 2025 -
 Maks Ferstappen Stal Ottsom Doch Lili
May 05, 2025
Maks Ferstappen Stal Ottsom Doch Lili
May 05, 2025 -
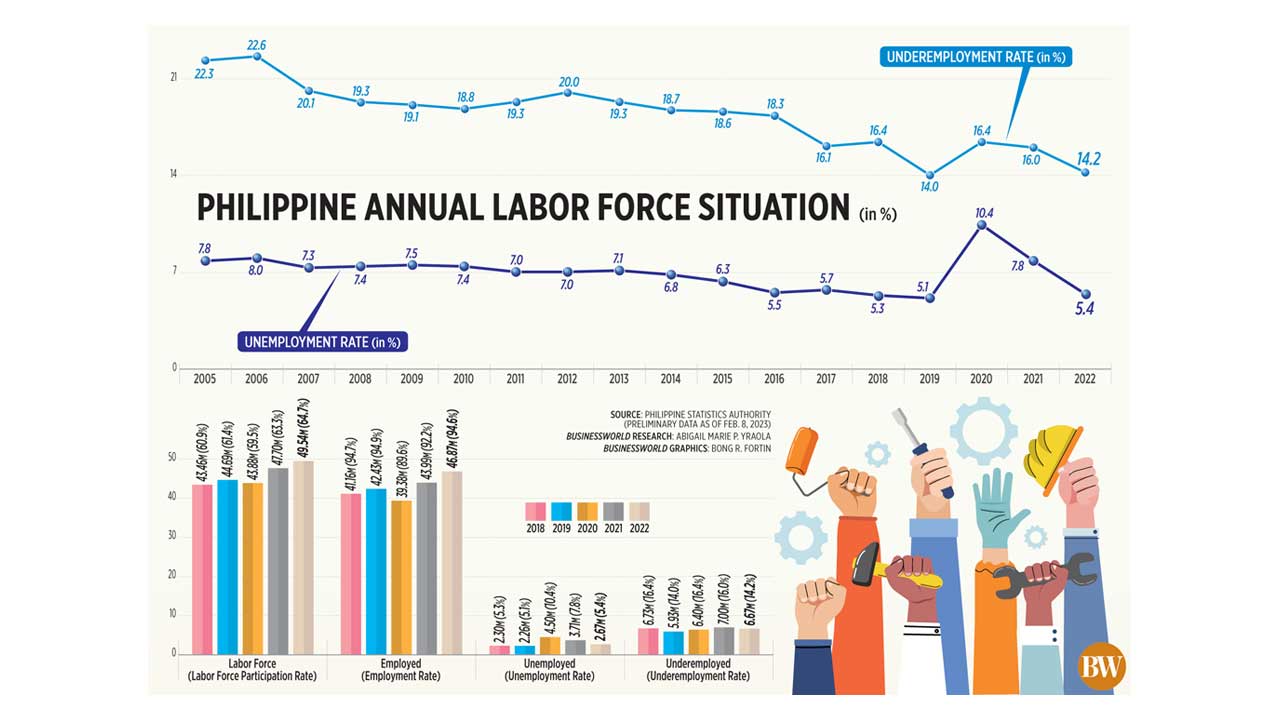 U S Employment Situation April 2023 Report Shows 177 000 Jobs Added
May 05, 2025
U S Employment Situation April 2023 Report Shows 177 000 Jobs Added
May 05, 2025 -
 Marvels Thunderbolts Examining The Potential For Success
May 05, 2025
Marvels Thunderbolts Examining The Potential For Success
May 05, 2025 -
 Meet The Jockeys Vying For Kentucky Derby 2025 Victory
May 05, 2025
Meet The Jockeys Vying For Kentucky Derby 2025 Victory
May 05, 2025
Latest Posts
-
 Unlocking Canadas Potential Gary Mars Focus On Western Economic Strategies
May 05, 2025
Unlocking Canadas Potential Gary Mars Focus On Western Economic Strategies
May 05, 2025 -
 Spotifys I Phone App Enhanced Payment System
May 05, 2025
Spotifys I Phone App Enhanced Payment System
May 05, 2025 -
 Sheins Stalled London Ipo The Us Tariff Fallout
May 05, 2025
Sheins Stalled London Ipo The Us Tariff Fallout
May 05, 2025 -
 Resistance Grows Car Dealerships Challenge Ev Mandate
May 05, 2025
Resistance Grows Car Dealerships Challenge Ev Mandate
May 05, 2025 -
 Updated Spotify I Phone App More Payment Choices
May 05, 2025
Updated Spotify I Phone App More Payment Choices
May 05, 2025

